Intro to git for scientists
Woodruff Lab
2024-10-11
Version control

The git model

Warning
Seeing the value of git often requires using it “well”, but using it well requires practice. Being motivated to practice is hard without seeing the value!
The git model
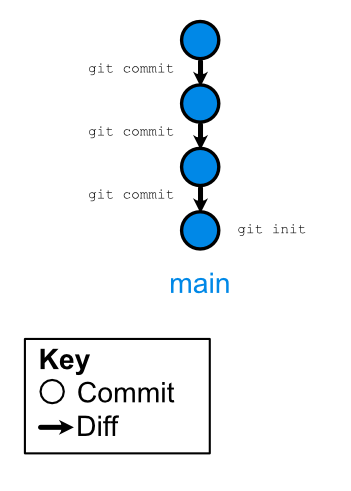
- Code versions are built on “diffs”; only changes from previous version are “saved”.
- Each diff is line-based; changing one character is recorded as deleting the line and inserting a new one
- Versions (“commits”) are always explicit
$ git checkout main
$ git reset --hard
$ git checkout -b revisions # create a new branch, and check it out
# make some edits to files
$ git commit -am 'made changes'
# make some edits to file1.txt and file2.txt
$ git add file1.txt
$ git commit -m 'Change file1'
$ git add file2.txt
$ git commit -m 'Change file2'
$ git checkout main
$ git merge revisions
see it in a terminal: https://asciinema.org/a/pFVUuEbZP6soYoYjvOKE1Eo52
$ git checkout main
$ git reset --hard
$ git checkout -b revisions # create a new branch, and check it out
# make some edits to files
$ git commit -am 'made changes'
# make some edits to file1.txt and file2.txt
$ git add file1.txt
$ git commit -m 'Change file1'
$ git add file2.txt
$ git commit -m 'Change file2'
$ git checkout main
$ git merge revisions
see it in a terminal: https://asciinema.org/a/pFVUuEbZP6soYoYjvOKE1Eo52
$ git checkout main
$ git reset --hard
$ git checkout -b revisions # create a new branch, and check it out
# make some edits to files
$ git commit -am 'made changes'
# make some edits to file1.txt and file2.txt
$ git add file1.txt
$ git commit -m 'Change file1'
$ git add file2.txt
$ git commit -m 'Change file2'
$ git checkout main
$ git merge revisions
see it in a terminal: https://asciinema.org/a/pFVUuEbZP6soYoYjvOKE1Eo52
$ git checkout main
$ git reset --hard
$ git checkout -b revisions # create a new branch, and check it out
# make some edits to files
$ git commit -am 'made changes'
# make some edits to file1.txt and file2.txt
$ git add file1.txt
$ git commit -m 'Change file1'
$ git add file2.txt
$ git commit -m 'Change file2'
$ git checkout main
$ git merge revisions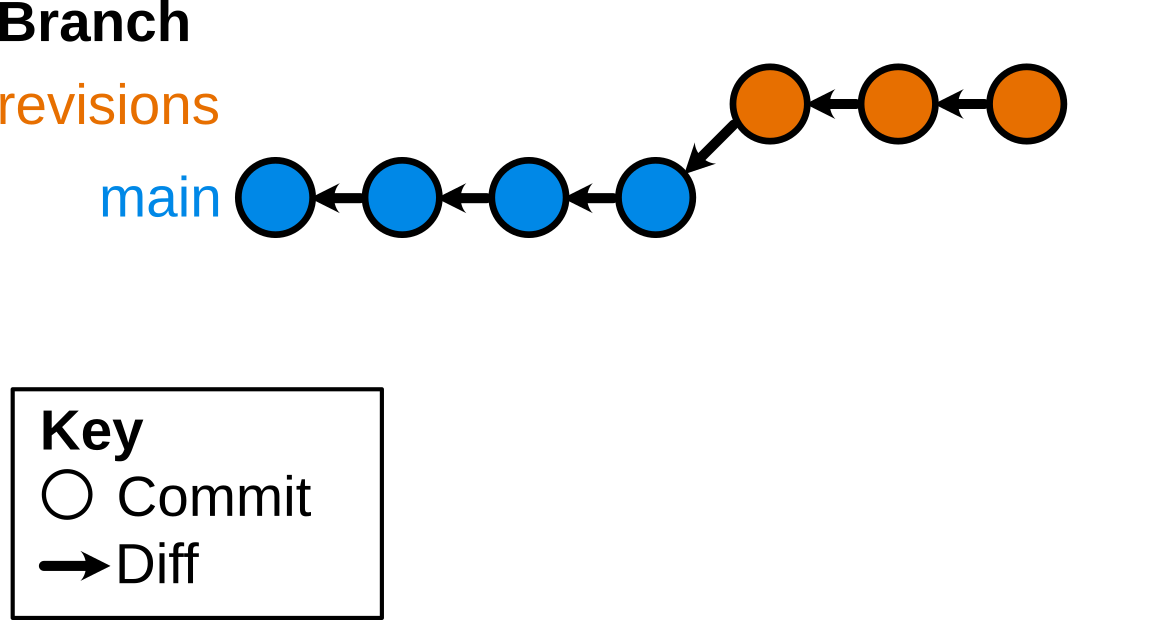
see it in a terminal: https://asciinema.org/a/pFVUuEbZP6soYoYjvOKE1Eo52
$ git checkout main
$ git reset --hard
$ git checkout -b revisions # create a new branch, and check it out
# make some edits to files
$ git commit -am 'made changes'
# make some edits to file1.txt and file2.txt
$ git add file1.txt
$ git commit -m 'Change file1'
$ git add file2.txt
$ git commit -m 'Change file2'
$ git checkout main
$ git merge revisions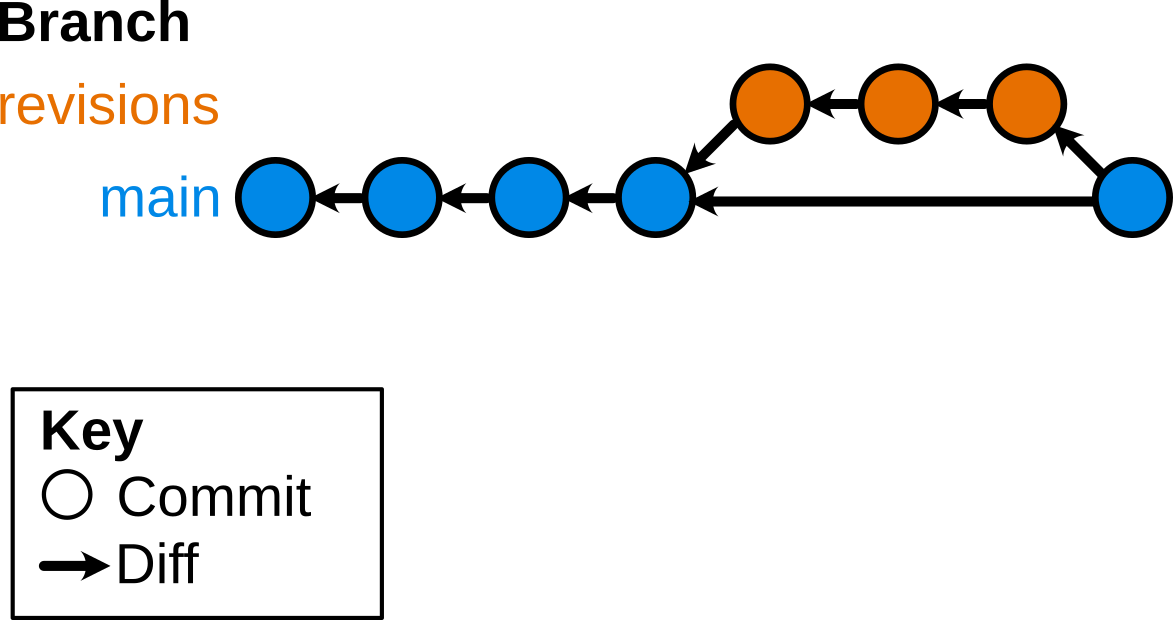
see it in a terminal: https://asciinema.org/a/pFVUuEbZP6soYoYjvOKE1Eo52
“Fast-foward” merge
$ git checkout main
$ git reset --hard
$ git checkout -b revisions # create a new branch, and check it out
# make some edits to files
$ git commit -am 'made changes'
# make some edits to file1.txt and file2.txt
$ git add file1.txt
$ git commit -m 'Change file1'
$ git add file2.txt
$ git commit -m 'Change file2'
$ git checkout main
$ git merge revisions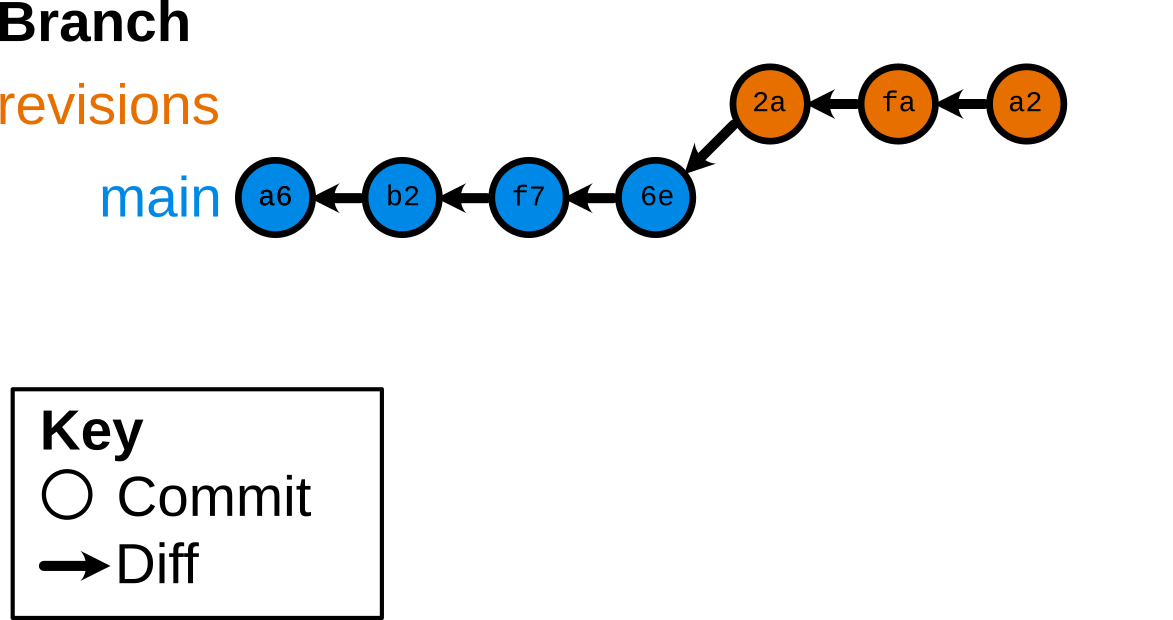
see it in a terminal: https://asciinema.org/a/pFVUuEbZP6soYoYjvOKE1Eo52
“Fast-foward” merge
$ git checkout main
$ git reset --hard
$ git checkout -b revisions # create a new branch, and check it out
# make some edits to files
$ git commit -am 'made changes'
# make some edits to file1.txt and file2.txt
$ git add file1.txt
$ git commit -m 'Change file1'
$ git add file2.txt
$ git commit -m 'Change file2'
$ git checkout main
$ git merge revisions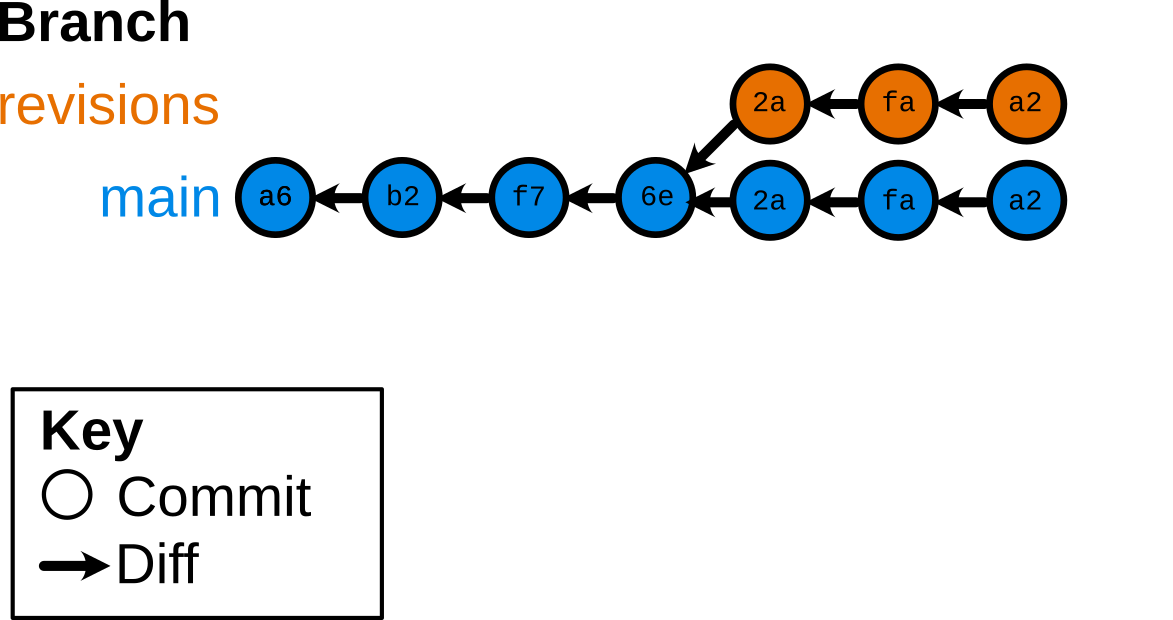
see it in a terminal: https://asciinema.org/a/pFVUuEbZP6soYoYjvOKE1Eo52
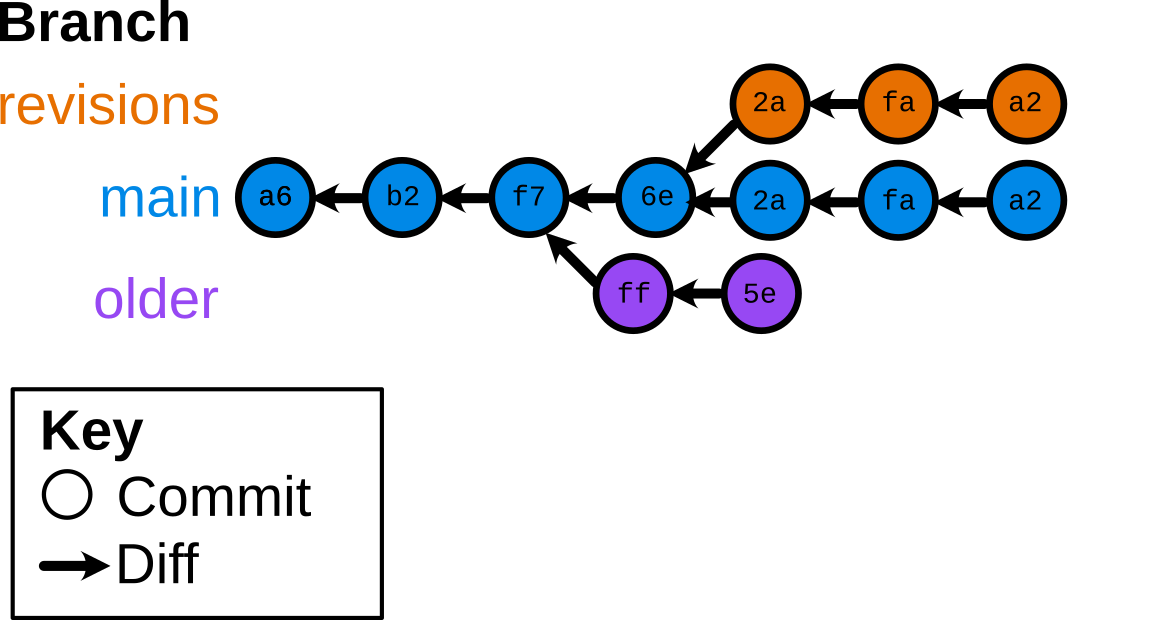
see it in a terminal: https://asciinema.org/a/5msKW2uk49gIf7UBmAuezihqY
Abandoning git
The Solution: use git!
It’s worth it!
I can help!
If that doesn’t fix it, git.txt contains the phone number of a friend of mine who understands git. Just wait through a few minutes of ‘It’s really pretty simple, just think of branches as…’ and eventually you’ll learn the commands that will fix everything.
git.txt
Kevin Bonham, PhD
Slack: Kevin Bonham
Github: https://github.com/kescobo
Gitlab: https://gitlab.com/kescobo
Web: https://blog.bonham.ch